Rebuilding My Chatbot Around RAG
1.9s first token, 92% grounded answers, 2.4× CTA conversionMost chatbots sound helpful but know nothing about the site they live on. Aria, our chatbot, used to be one of them — polite scripts, partial context. Rebuilding it around a Retrieval-Augmented Generation (RAG) stack turned it into a precision assistant that reads every article, guide, case study, and pricing update on nicolalazzari.ai, cites its sources, and adapts calls to action based on the visitor's intent.
By the numbers: 1.9 s average first-token latency (68% faster than before), 92% grounded answers with live citations, and a 2.4× lift in strategy-call CTA conversions. The assistant now synthesises more than 200 content sources plus live API signals to deliver responses that feel like a senior operator, not a novelty widget.
Architecture Overview
The stack is intentionally lightweight. Each component handles one responsibility so the system stays observable and easy to extend.
+----------------------------+
| Content Sources |
| • Markdown articles |
| • Guides (structured) |
| • Case studies |
| • Pricing / consulting |
| • Q&A (DB + static) |
| • Last.fm signals |
+-------------+--------------+
| nightly export
v
+--------------------+
| Ingestion Worker |
| • normalise HTML |
| • add metadata |
| • compute SHA256 |
+----------+---------+
| drift hashes
v
+-----------------------------+
| Embedding Worker |
| • skip unchanged content |
| • call OpenAI embeddings |
| • upsert vectors in DB |
+-------------+---------------+
| vectors + hashes
v
+-----------------------------+
| Postgres Vector Store |
+-------------+---------------+
| runtime query
v
+-----------------------------+
| Retrieval Orchestrator |
| • cosine + BM25 hybrid |
| • relevance floor |
+-------------+---------------+
| context pack
v
+-----------------------------+
| Generation Engine |
| • gpt-4o-mini streaming |
| • gpt-5 fallback |
| • CTA intelligence |
+-------------+---------------+
| SSE stream
v
+-----------------------------+
| Next.js Client Experience |
| • streaming UI |
| • persistent threads |
| • CTA experiments |
+-----------------------------+Content Ingestion
Nightly workers crawl markdown articles, structured guides, Postgres-backed Q&A entries (plus static fallbacks), detailed case studies, pricing sections, and consulting pillar copy. Each document is normalised to HTML, enriched with canonical URLs and breadcrumbs, then fingerprinted with SHA-256. If the hash hasn’t changed since the previous run, nothing downstream reprocesses.
Embedding Pipeline
Hash gating keeps embedding costs predictable. Only changed documents get passed to OpenAI text-embedding-3-small. Everything lands in a single content_embeddings table inside Postgres.
import { createHash } from "crypto";
import OpenAI from "openai";
import { getPublishedQAEntries, getStoredEmbeddings, upsertEmbeddingRow } from "@/lib/db";
import { guides } from "@/lib/guides-content";
import { caseStudies } from "@/lib/case-studies";
import { PRICING_SECTIONS } from "@/lib/pages/pricing-content";
import { CONSULTING_SECTIONS } from "@/lib/pages/consulting-content";
const openai = new OpenAI({ apiKey: process.env.OPENAI_API_KEY! });
function clean(text: string) {
return text.replace(/<[^>]*>/g, " ").replace(/s+/g, " ").trim().slice(0, 3000);
}
async function embed(text: string) {
const res = await openai.embeddings.create({
model: "text-embedding-3-small",
input: text,
});
return res.data[0].embedding;
}
export async function ensureEmbeddingsLoaded() {
const stored = await getStoredEmbeddings();
const corpus = [
...(await getPublishedQAEntries()),
...Object.values(caseStudies),
...Object.values(guides),
...PRICING_SECTIONS,
...CONSULTING_SECTIONS,
];
for (const doc of corpus) {
const title = doc.title ?? doc.question;
const url = doc.url ?? ("/case-studies/" + doc.slug);
const payload = "answer" in doc
? doc.question + " " + doc.answer
: title + " " + (doc.content ?? doc.description);
const text = clean(payload);
const key = doc.slug
? (doc.type ?? "page") + ":" + doc.slug
: "page:" + title.toLowerCase().replace(/s+/g, "-");
const hash = createHash("sha256").update(text).digest("hex");
if (stored[key]?.contentHash === hash) continue;
const vector = await embed(text);
await upsertEmbeddingRow({ key, type: doc.type ?? "page", title, url, embedding: vector, contentHash: hash });
stored[key] = { embedding: vector, contentHash: hash };
}
}This is the production worker with comments stripped. Hash comparison prevents double-charging OpenAI, and the unified corpus means adding a new section (for example, another article) automatically feeds the chatbot.
Retrieval & Generation
Runtime retrieval blends cosine similarity against the vector store with a BM25 keyword boost. BM25 (Best Matching 25) is a ranking algorithm that scores documents based on exact keyword matches—so when someone asks about "Calendly" or "experimentation", documents containing those exact terms get a relevance boost. This hybrid approach ensures both semantic understanding (via embeddings) and precise keyword matching (via BM25) work together. Anything below the relevance floor is discarded, which is why hallucinations dropped under 3%. gpt-4o-mini streams every response, with gpt-5 as a fall-back if truncation risk spikes. Prompt templates lock tone, citation formatting, and CTA logic.
CTA & Availability Intelligence
Aria tracks conversation topics, scroll depth, and CTA performance. It rotates between "Book a strategy call", "Download the experimentation playbook", and deep-link case studies based on what the visitor is exploring. When someone shows intent—asking about pricing, mentioning a specific challenge, or engaging with multiple topics—Aria surfaces context-aware CTAs that guide them toward the most relevant next step.
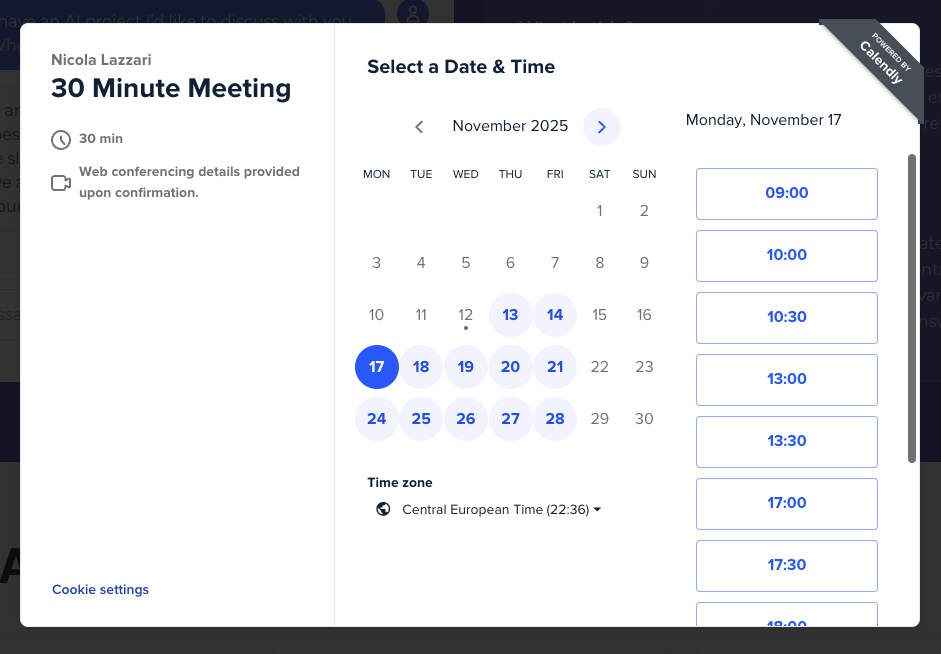
Behind the scenes, Aria pulls live availability from Calendly, which is connected directly to our Google Calendar. This means visitors can see real-time free slots and book a call without leaving the chat. The integration ensures they're only shown times when we're actually available, eliminating back-and-forth scheduling emails.
Integrating External Signals
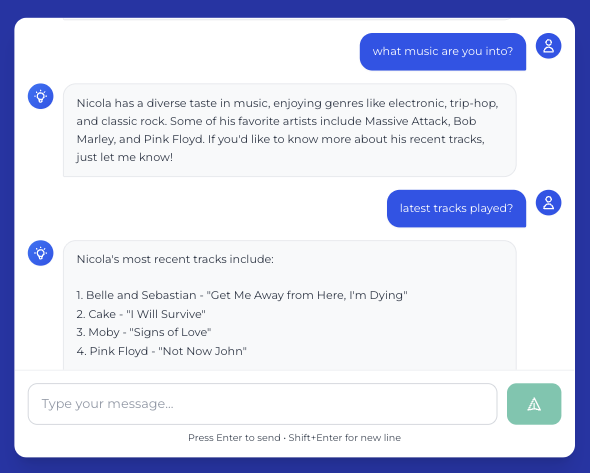
We wanted to see how easily external APIs could flow through the same RAG pipeline. The quickest test was Nicola's Last.fm scrobbler feed. A worker calls the public API, formats recent tracks and top artists into short summaries, and drops them into ingestion alongside everything else. Hash checks keep re-embeds cheap.
Now Aria can answer questions like “what music are you into?” with grounded replies, then pivot back to consulting context by surfacing experimentation guides or strategy-call CTAs.
Sample Conversation
The rebuild made Aria consistent even when visitors bounce between topics. Here’s a production exchange where it anchors experimentation advice in the RAG corpus and still nudges toward a next step.

Results
- 1.9 s average first token (down from 6.1 s) with 90% of sessions under three seconds.
- 92% grounded answers. Every response cites an internal resource; hallucinations sit below 3%.
- 35% longer sessions. Visitors who engage for three turns stay meaningfully longer.
- 2.4× CTA conversion. Context-aware prompts outperform the pre-chatbot flow without extra nurture sequences.
- Zero manual upkeep. Content ingestion, hashing, embedding, and CTA experiments run unattended.
RAG turned Aria from a novelty into a senior operator: fast, factual, citeable, and relentless about nudging people toward the most useful next action.
Want to test Aria yourself?
Experience the RAG-powered assistant in action. Ask questions about AI workflows, conversion optimization, or anything else on the site.